
美人鱼究竟长什么样?(当然希望不是图中这样)
美人鱼究竟长什么样?(当然希望不是图中这样) 安徒生童话里那个眼睛像星星一样、歌声美丽动人的小美人鱼大概是我们所有人对美人鱼最初的印象,纯洁、美丽、心地善良。人类历...
2024-11-21 01:45:56

如何花式计算20的阶乘?
今天刷知乎看到个挺有意思的问题:
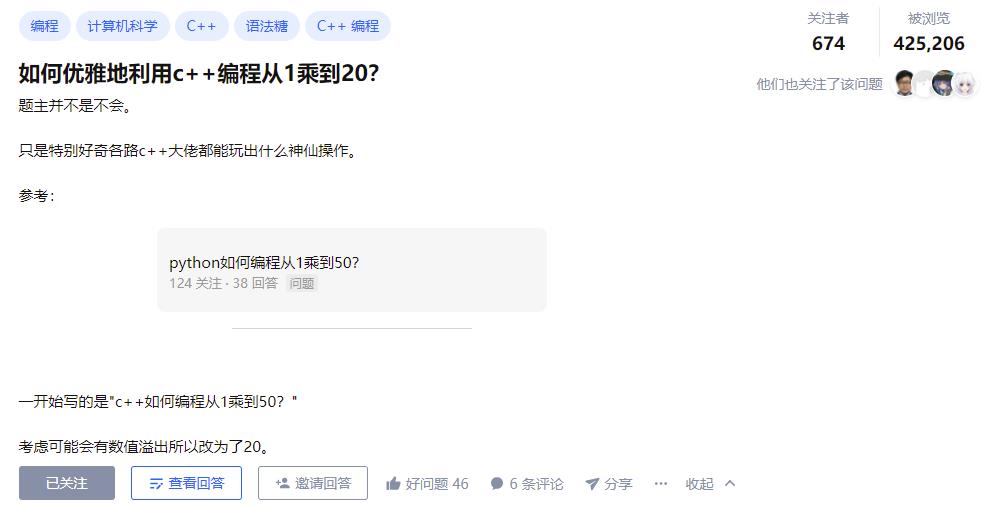
我想这有啥难的,还能写出花来不成?结果看到高赞回答,感觉自己的智商有点不够用了。
随便来看一个高赞回答是怎么写的:

这个其实还算比较简单的,没啥难度,还有更晦涩的:
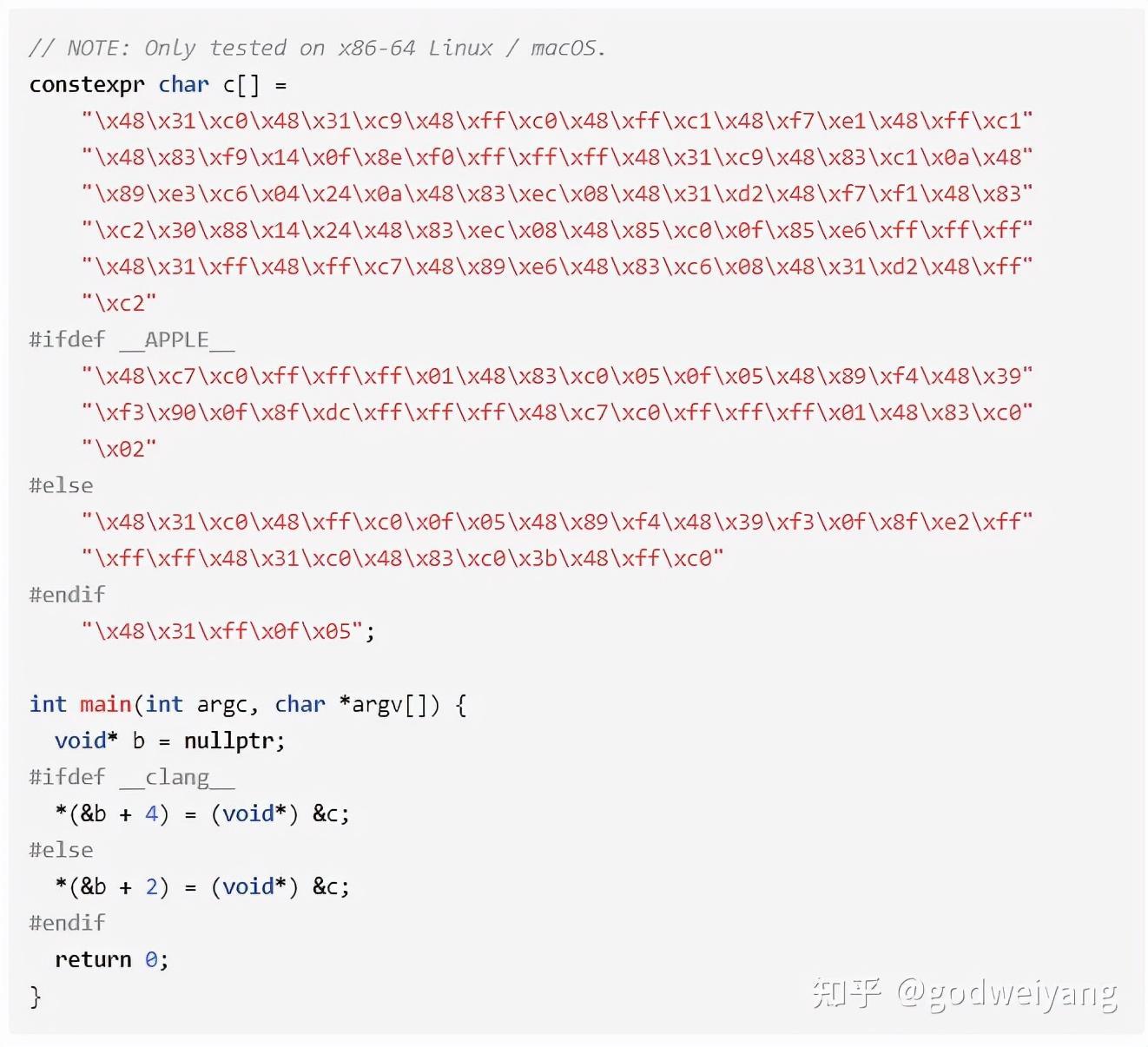
这个乍一看根本看不懂在写啥,当然平时也很少会写这种晦涩的代码。
今天我就教大家用CUDA来计算一下20的阶乘,就当作是CUDA的一个入门例子。
先来看看我的回答:
如何优雅地利用c++编程从1乘到20?13 赞同 · 2 评论回答
我提供了两种CUDA的实现方法。
#includetypedef unsigned long long int ull;
const int N = 20;
__device__ ull atomicMul(ull* address, ull val) {
ull *address_as_ull = (ull *)address;
ull old = *address_as_ull, assumed;
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, val * assumed);
} while (assumed != old);
return old;
}
__global__ void mul(ull *x) {
ull i = threadIdx.x + 1;
atomicMul(x, i);
}
int main() {
ull *x;
cudaMallocManaged(&x, sizeof(ull));
x[0] = 1;
mul<<>>(x);
cudaDeviceSynchronize();
std::cout << x[0] << std::endl;
cudaFree(x);
return 0;
}这个方法使用原子操作,一共20个线程,每个线程负责一个乘数,然后一起乘到x[0]上。
但是由于并行执行,线程之间没有先后顺序,会导致同时乘的时候产生冲突,所以需要使用原子操作。在某一个线程将它的乘数乘到x[0]上时,不会被其他线程打断。也就是会加锁,同一时刻只会有一个线程在进行乘法操作。
但是由于CUDA只提供了加法和减法的原子操作(atomicAdd和atomicSub),所以得自己实现乘法的原子操作atomMul,利用的是atomicCAS操作,也就是compare and swap ,如果目标地址元素和待比较的元素相同,就进行元素的交换,否则不进行任何操作。
可以看出,在atomicMul函数的do while循环中,先用old变量保存x[0]处的当前值,这时候如果有其他线程在x[0]处写入了新的值,那么接下来该线程的atomicCAS操作就会判断元素不相同,不进行任何操作,重新执行下一轮循环。
#includetypedef unsigned long long int ull;
const int N = 20;
const int WARP_SIZE = 32;
__global__ void mul(ull *x) {
int i = threadIdx.x;
ull val = x[i];
for (int mask = WARP_SIZE / 2; mask > 0; mask >>= 1)
val *= __shfl_xor_sync(WARP_SIZE - 1, val, mask, WARP_SIZE);
x[i] = val;
}
int main() {
ull *x;
cudaMallocManaged(&x, WARP_SIZE * sizeof(ull));
for (int i = 0; i < WARP_SIZE; ++i)
x[i] = i < N ? i + 1 : 1;
mul<<>>(x);
cudaDeviceSynchronize();
std::cout << x[0] << std::endl;
cudaFree(x);
return 0;
}这种方法使用线程束原语__shfl_xor_sync,只要线程在同一个线程束中(32个线程),就可以获取其他线程的值,异或运算后写入指定地址。详细原理这里就不解释了,可以简单理解为:
一共进行5轮操作。第一轮操作之后,下标为0-15的位置分别保存着下标0+1、2+3、一直到30+31的结果。第二轮操作之后,下标为0-7的位置分别保存着下标0+1+2+3、4+5+6+7、一直到28+29+30+31的结果。最后一轮之后,下标为0的位置保存着所有32个元素之和。
所以只需要在开始时,分配一个大小为32的数组,前20个元素分别保存1-20,后面12个元素是为了满足线程束大小32的条件,赋值为1就行了。
方法2需要额外开辟大小为32的数组,空间存在浪费,并且数组赋值也需要时间。
感谢@NekoDaemon老哥提供的优化建议,只需要在计算的时候根据线程号计算对应乘积元素就行,但是线程数仍然需要分配32个。
#includetypedef unsigned long long int ull;
const int N = 20;
const int WARP_SIZE = 32;
__global__ void mul(ull *x) {
int i = threadIdx.x;
ull val = i < N ? i + 1 : 1;
for (int mask = WARP_SIZE / 2; mask > 0; mask >>= 1)
val *= __shfl_xor_sync(WARP_SIZE - 1, val, mask, WARP_SIZE);
if (!i) x[i] = val;
}
int main() {
ull *x;
cudaMallocManaged(&x, sizeof(ull));
mul<<>>(x);
cudaDeviceSynchronize();
std::cout << x[0] << std::endl;
cudaFree(x);
return 0;
}代码保存为run.cu,然后执行nvcc run.cu -o run,最后执行./run,就会出来结果2432902008176640000。
今天没有讲解CUDA编程的基础概念,适合有一定基础的同学阅读,如果有对CUDA感兴趣的同学,可以在评论区留言,下次专门写一个CUDA入门系列教程。关注我的公众号【算法码上来】,每天跟进最新文章。
2024-11-21 01:45:56

2024-11-21 01:43:43

2024-11-21 01:41:30
2024-11-21 01:39:17

2024-11-21 01:37:04

2024-11-21 01:34:51

2024-11-21 01:32:38

2024-11-21 01:30:26

2024-11-21 01:28:13

2024-11-21 01:26:00

2024-11-21 01:23:47

2024-11-21 01:21:34

2024-11-21 01:19:21
2024-11-21 01:17:09

2024-11-21 01:14:56

2024-11-21 01:12:43

2024-11-21 01:10:30

2024-11-21 01:08:17

2024-11-21 01:06:04

2024-11-21 01:03:52